- 更新:2020-07-21 00:21:16
- 首发:2020-07-21 00:14:40
- 教程
- 6482
如果使用Chrome浏览器访问XML地址,返回报错信息:
Input is not proper UTF-8, indicate encoding !
Bytes: 0x08 0xE6 0xBA 0x90
这是由于返回回来的数据存在ASCII控制字符。XML规范不支持这部分控制字符。
这个报错提示是Chrome浏览器生成的报错,不是服务器端返回的报错。
关于该报错的详细信息请参阅:《PRB: Error Message When an XML Document Contains Low-Order ASCII Characters》。
解决方法
使用正则替换这部分控制字符\x00-\x1F\x7F或替换不可打印字符\x00-\x1F\x7F-\x9F。
JavaScript:
'string'.replace(/[\x00-\x1F\x7F]/g, '')
控制字符是 ASCII 范围0-31中特殊的不可见字符。正常情况下这些字符很少用在 JavaScript 中,包含这些字符的正则表达式很可能编写有误,因此部分ESLint规则可能将其视为错误,可将该行设置no-control-regex: "off"。
JAVA:
Regex.Replace(xmlStr, "[\x00-\x1F\x7F]","");
总结与额外发现
刚开始遇到这个问题,以为类似MySQL存储字符宽度超过3个字节的UTF8编码的问题。尝试过删除文本中的Emoji表情,但是仍然没能解决问题。但是在探索过程中发现了JS过滤Emoji表情的准确方法。
JavaScript引擎把utf-16的4字节字符,拆分成两个ucs-2的2字节字符。因此4字节utf-16在js中被用两个字符来表示,高位范围为0xD800 - 0xDBFF,低位范围为0xDC00 - 0xDFFF。
因此,检测包括Emoji表情在内的utf-16字符可以使用正则表达式/[\ud800-\udbff][\udc00-\udfff]/g进行过滤,即过滤utf8非3字节编码的字符串。
H = char.charCodeAt(0) // 取出高位
L = char.charCodeAt(1) // 取出低位
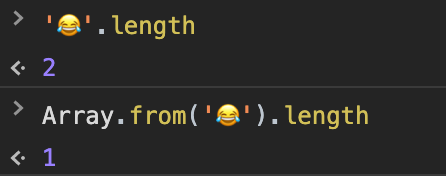
判断包含Emoji表情的字符串长度,需要使用
Array.from(string).length
来代替string.length。
本站RSS订阅地址:https://www.wyr.me/rss.xml。
暂无内容




老师你好,我希望能用一个openwrt路由器实现IPv4和IPv6的桥接,请问我该如何实现?我尝试了直接新增dhcpv6的接口,但是效果不甚理想(无法成功获取公网的ipv6,但是直连上级路由的其他设备是可以获取公网的ipv6地)
你好
,为什么我这里是0039 813C 0600 0075 16xx xx xx,只有前6组是相同的,博客中要前8位相同,这个不同能不能照着修改呢?我系统版本是Win1124H2
大神你好,win11专业版24h2最新版26100.2033,文件如何修改?谢谢
win11专业版24h2最新版26100.2033,Windows Feature Experience Pack 1000.26100.23.0。C:\Windows\System32\termsrv.dll系统自带的这个文件,39 81 3C 06 00 00 0F 85 XX XX XX XX 替换为 B8 00 01 00 00 89 81 38 06 00 00 90。仍然无法远程连接。原来是win11 21h2系统,是可以远程链接的。共享1个主机,2个显示器,2套键鼠,各自独立操作 各自不同的账号,不同的桌面环境。
博主,win11专业版24h2最新版,C:\Windows\System32\termsrv.dll系统自带的这个文件,找不到应该修改哪个字段。我的微信:一三五73二五九五00,谢谢